

This is part 3 of a blog series of a talk I gave at Droidcon NYC and Londroid earlier this year. Dagger has a steep learning curve that frequently leaves developers not wanting to explore it further once they've integrated it. This series attempts to show some neat "party tricks" and other clever Dagger patterns to inspire more advanced usage.
The single biggest benefit of Dagger is that it generates all the boilerplate glue code for you. Rename a class? Add a parameter? Move a class? Dagger's got you! That said, there are some patterns that can make Dagger code easier or harder move around when refactoring. This post will dive into some common points of friction and how playing to Dagger's strengths can actually help you avoid them.
Directionality
The Problem
Consider this Dagger module
@Module
class MyGiantModule {
// Other provisions...
@Provides
fun provideSeasoning() = Seasoning()
@Provides
fun provideTaco(seasoning: Seasoning) = Taco(seasoning)
}
It's a simple setup! Users usually just want the Taco but seasoning is pulled out to an inner implementation detail provider. Now, say I want to incrementally refactor this module into a SeasoningModule and TacoModule. A common pattern I see is to pull out the TacoModule first, because that's what most users are directly looking for. Now we have this:
@Module
class MyGiantModule {
// Other provisions...
@Provides
fun provideSeasoning() = Seasoning()
}
@Module(includes = [MyGiantModule::class])
class TacoModule {
@Provides
fun provideTaco(seasoning: Seasoning) = Taco(seasoning)
}
I like to call this "pulling out from the top", and I think it's usually a bad way to refactor. Now, you've still got MyGiantModule, but you've also got this new @TacoModule. You've created cognitive overhead because consumers don't necessarily know which one to use and you have to migrate all consumers immediately to use TacoModule now. Not only this, but if they still used anything else in MyGiantModule, then you've got an awkward scenario where you're still depending on both. That's free, fresh off the line tech debt!
Future iterations will continue to incur churn as well. Maybe you actually want to name it something else? Maybe you want to change direction with how you're refactoring it? More churn!
The Solution
Instead, I like to "pull out from the bottom". In this approach, your effective current public API (MyGiantModule) remains the entry point for consumers the entire time while you're refactoring.
@Module(includes = [TacoModule::class])
class MyGiantModule {
// Other provisions...
@Provides
fun provideSeasoning() = Seasoning()
}
@Module
class TacoModule {
@Provides
fun provideTaco(seasoning: Seasoning) = Taco(seasoning)
}
It's a subtle difference, but it's a significant win for both reducing risk and iterating quickly. In this approach there's zero churn on consumers during the refactoring, allowing you to freely explore different designs for your extracted modules under the hood.
@Module(includes = [TacoModule::class, SeasoningModule::class])
class MyGiantModule {
// Other provisions...
}
@Module
class TacoModule {
@Provides
fun provideTaco(seasoning: Seasoning) = Taco(seasoning)
}
@Module
class SeasoningModule {
@Provides
fun provideSeasoning() = Seasoning()
}
This can go on for as long as you need!
@Module(includes = [TacoModule::class])
class MyGiantModule { }
@Module(includes = [SeasoningModule::class])
class TacoModule {
@Provides
fun provideTaco(seasoning: Seasoning) = Taco(seasoning)
}
@Module
class SeasoningModule {
@Provides
fun provideSeasoning() = Seasoning()
}
Until finally, when you're ready to remove MyGiantModule. By the end, it's just an empty shell that just includes other refactored modules it's composed of. Removing it can be done in a single atomic migration. ...Or you can even just deprecate it at this point and prevent new code from using it; it depends on your codebase and your constraints.
The important lesson here is that your public API of your initial module never changed during the entire refactoring process. This is extremely powerful when modularizing projects. This tactic works for other areas too!
- Splitting dependency artifacts. Think like Android's old support-v4 monolith: by the end, it was just a shim pointing to other artifacts.
- Classic case: changing implementation classes that are only exposed as interfaces.
Constructor injection
In the previous example, we're providing every dependency via @Provides + a Dagger module. This works, however you should only use @Provides if absolutely necessary. For your own types, where possible, you should almost always prefer constructor injection.
A quick TL;DR of constructor injection
Instead of manually instantiating each type in a provider function, constructor injection is just the act of annotating your type's constructor with @Inject and allowing Dagger to handle instantiating it for you. This is common in most DI libraries, but uncommon in Android due to the framework often not offering the ability to define your own constructor for framework types. That's changing now, but it's out of scope for this blog post.
Consider our Seasoning provision
@Module
class SeasoningModule {
@Provides
fun provideSeasoning() = Seasoning()
}
With constructor injection, we can eliminate the module entirely.
class Seasoning @Inject constructor()
If you want to scope or qualify it, simply annotate it with your desired scope or qualifier annotation.
@InternalApi
@Singleton
class Seasoning @Inject constructor()
internal/file-private (Kotlin).Connecting the dots
We can actually do this with our entire example. The following two lines of code are functionally equivalent to the two modules we had before!
class Taco @Inject constructor(seasoning: Seasoning)
class Seasoning @Inject constructor()
Dagger will automagically connect all the dots for you in this case, no modules or providers necessary. Look how much simpler that is! If we'd started with this in the first place, we could have skipped the refactoring churn entirely. That's the point I want to drive home with this example too: constructor injection is useful for a number of well documented reasons, and it's also incredibly valuable for enabling refactoring work.
This works across compilation boundaries as well. The Android/JVM community is actively moving toward modularizing builds and refactoring work like this example is often done for modularization reasons. We could split the Taco and Seasoning class into two different projects and Dagger would still work.
For the sake of argument, we're going to say each of these are implemented in a different Gradle subproject.
// :taco subproject, depends on :seasoning
class Taco @Inject constructor(seasoning: Seasoning)
// :seasoning subproject
class Seasoning @Inject constructor()
In this case, while processing Taco, Dagger's processor will introspect Seasoning's class, recognize its injected constructor, and generate a factory ("Seasoning_Factory") for it.
This happens even if dagger's compiler only runs over :taco (i.e. the project has a kapt/annotationProcessor 'com.google.dagger:dagger-compiler:{version}' build dependency) and not over :seasoning.
A word about dagger-compiler
If no generated factory currently exists for the dependency Dagger's looking for, it will generate a new one. In the current example, the final jar will have something like this. Note the legend in the upper left corner!

Dagger has gone ahead and generated a Seasoning_Factory for us in :taco. This works. You won't get any complaints at compile-time, and it looks Fine™️ that Seasoning is annotated and available for injection.
Now let's add a dinner class+project that consumes :taco.

In this case - Dagger is recognizing that Taco already has a Taco_Factory class generated for it and will just reuse it.
There's a problem here though. Let's add a twist - a new :nacho project that's a sibling to :taco. It also consumes :seasoning and is consumed by :dinner, just like :taco. Can you spot the problem?
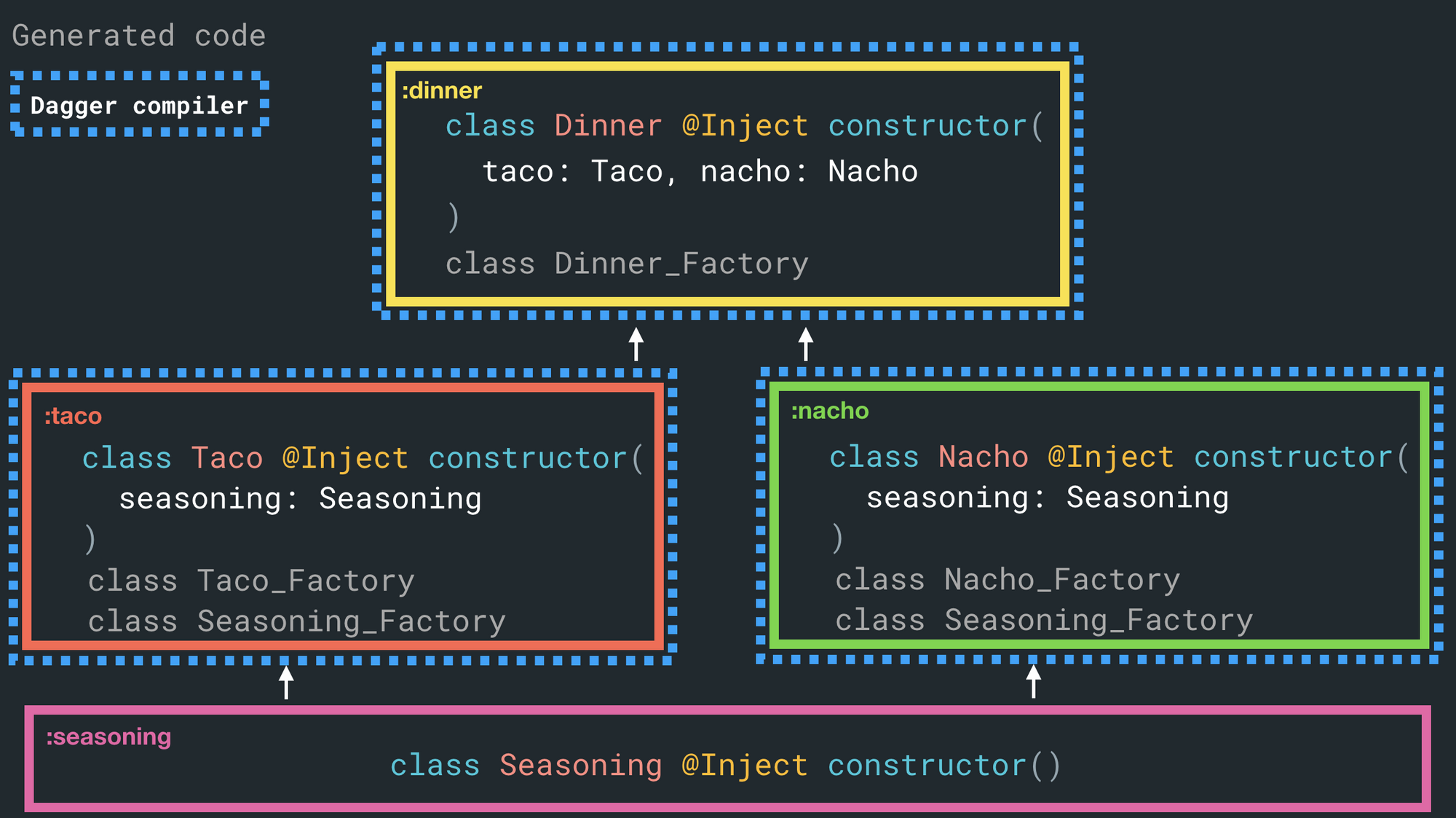
We're now generating two Seasoning_Factory classes! One in each of :taco and :nacho.
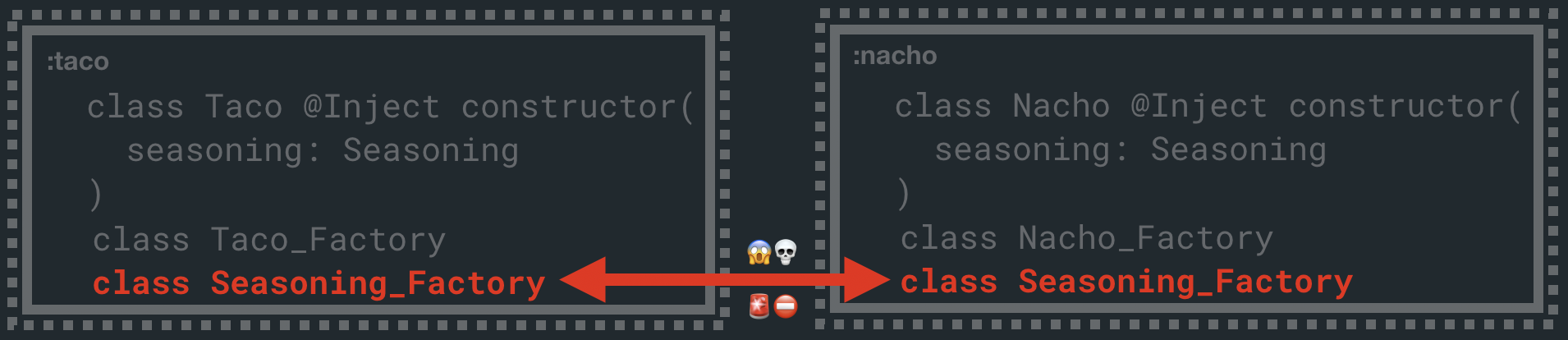
This will cause a class conflict in the dinner project, and the solution is to run the compiler one level lower on the :seasoning project as well.
When we do this with the example above, the Seasoning_Factory class is just generated once in the :seasoning project, then all future consumers will reuse the single generate class. You're also saving yourself a bit of duplication work here since it's now only generated once.
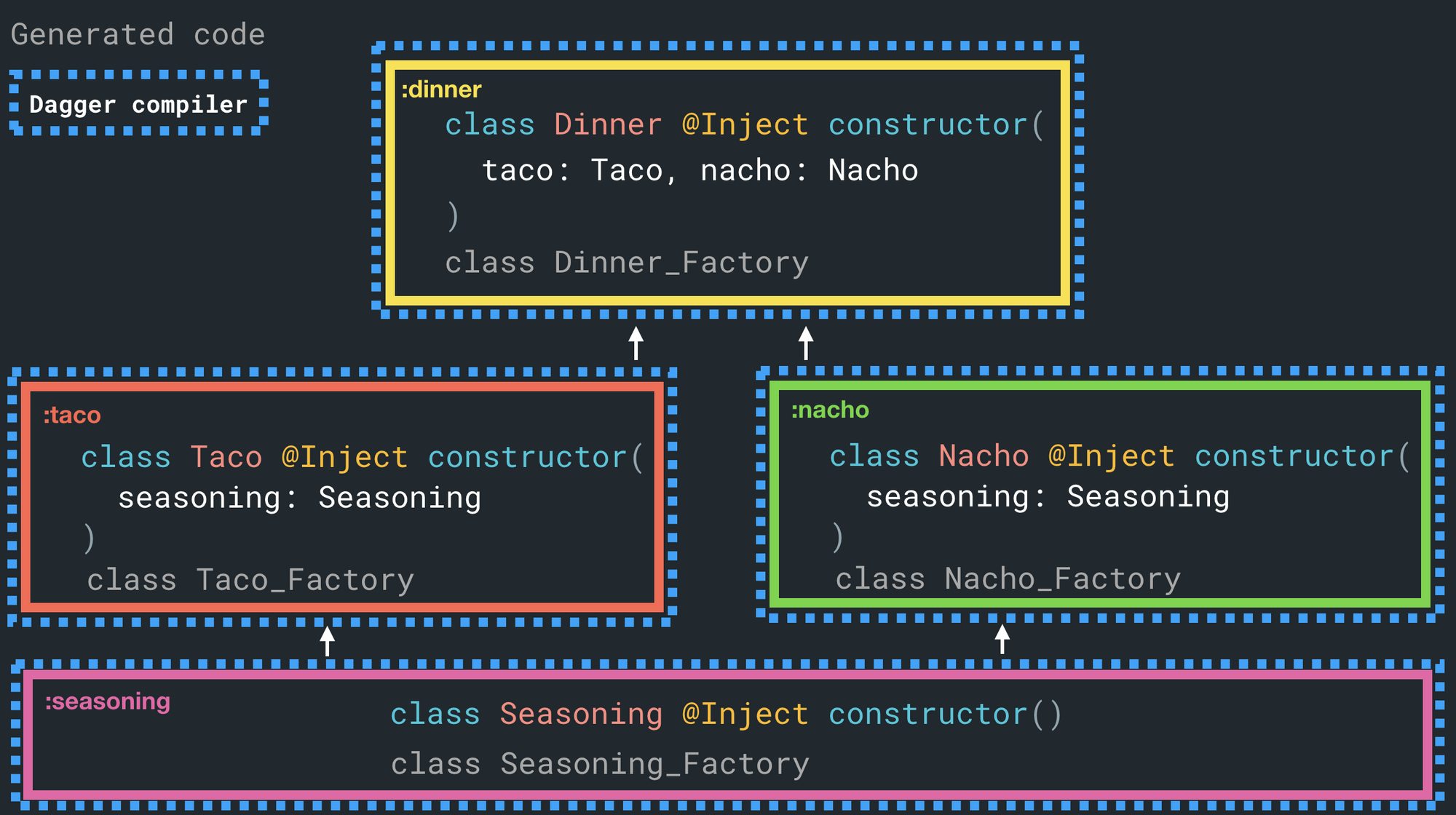
The trick here is simple: any project you have constructor injection, you should run the dagger compiler over it too.
Reiterating - by this I mean you should be running kapt/annotationProcessor 'com.google.dagger:dagger-compiler:{version}' on that project.Edit: César Puerta informed me there's an annotation processor option you can pass to Dagger to warn on this behavior: dagger.warnIfInjectionFactoryNotGeneratedUpstream
Edit 2: Reddit user /u/Pzychotix pointed out that you want to defend against this in kotlin projects because Kapt incremental processing doesn't correctly handle originating elements from different compilation units: https://youtrack.jetbrains.com/issue/KT-34309.
Hope this was helpful! In short, there's three takeaways here:
- Pull out from the bottom!
- Use constructor injection! Aside from their obvious benefits, they also reduce the "public API" footprint of your Dagger modules.
- Run the dagger compiler anywhere you use
@Inject!
With those three in mind, you'll be able to seamlessly refactor Dagger code without headaches. Thanks for getting through the denser examples above and arriving to the end. As a reward, here's a picture of one of my sister's dogs, Ziggy.

Thanks to Ben Weiss for proofreading this.