

My team recently cleaned up an API in an internal storage library. While it’s a simple case, it covers a couple interesting language tools and tradeoffs. Let’s dig in!

It’s a function called enumStoreKeys that returns a Set of StoreKey enums for a given classKey. StoreKey is just an interface and we use enum implementations of it. To make the enum bit explicit we literally have it in the function name.
How can we make this better?
Removing Footguns
Right off the bat, there’s an obvious footgun here: this only applies to enums and will fail if you give it a class that isn’t an enum. Can we make that more explicit? Particularly in a way that doesn’t wait until runtime to find out?
We could mark it in the generic

But now we’ve lost the StoreKey. How do we keep both?

The answer is a somewhat little-known feature of Java and Kotlin called Intersection Types. In short — you can mark a generic as extending one class and also require that it implement certain interfaces. The syntax for this in both languages can be a bit surprising if you haven’t seen it before:

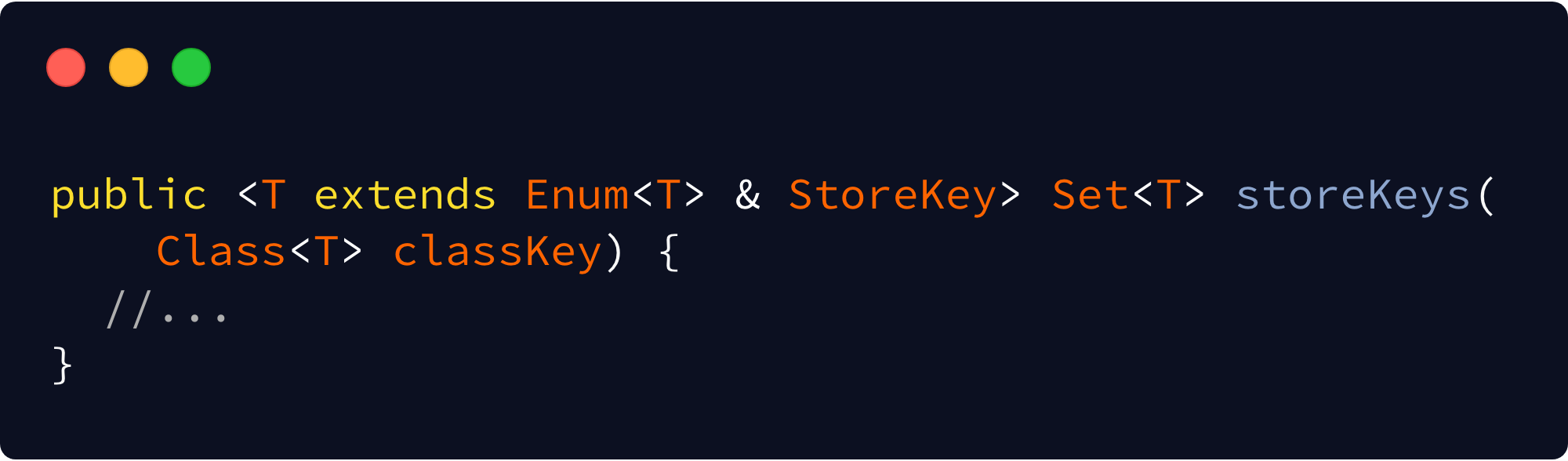
Boom. Now the compiler’s going to enforce this for us. No runtime checks needed, and the user’s going to be bounced into doing the right thing immediately. We can even remove the redundant enum prefix to the name now too.
This falls into a grey areas as far as whether or not it’s a breaking change. By the letter of the law, it technically isn’t a breaking change at runtime. Is does potentially break calling code though at compile-time with the stricter requirements. As it’s also basically enforcing what was already enforced at runtime, it’s the kind of change I’d possibly make even in a semantically versioned project (without the rename of course). It’s tricky though, and you’d have to take each on a case-by-case basis. In our code base though, we just made the switch. This also revealed several incorrect usages that would have always failed (were always failing?) at runtime.
Optimization
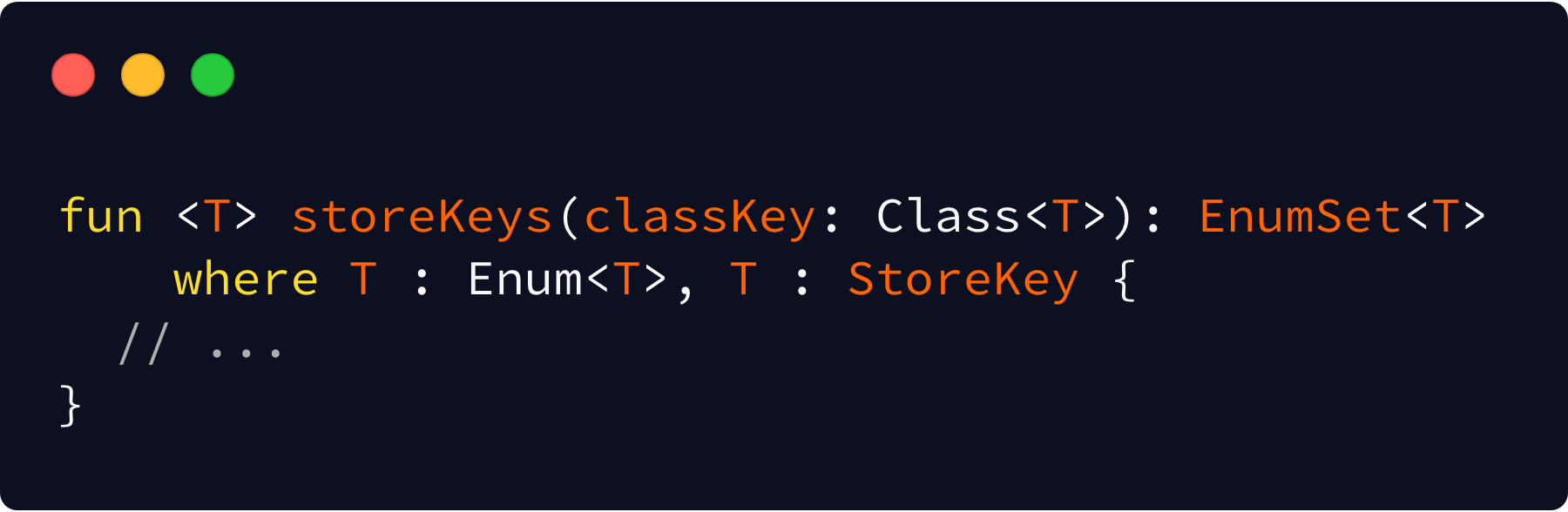
The next thing we can improve here is the return type. Right now we just return a simple Set, which is fine for all intents and purposes. However, we just made the enum nature of the type explicit. Does that buy us anything? Yes!
Java has a special Set implementation just for enums called an EnumSet. From its doc:
A specialized Set implementation for use with enum types. … EnumSets are represented internally as bit vectors. This representation is extremely compact and efficient. The space and time performance of this class should be good enough to allow its use as a high-quality, type-safe alternative to traditional int-based "bit flags."
Sounds great! As it’s just a custom Set implementation, this is actually a non-breaking API change for source compatibility. We had to do a bit of work to make our implementation conform to this return type (namely — EnumSet doesn’t allow you to just give it an empty set to create from), but that’s a work load we’re happy to take on for our users. In the end, they get an optimized implementation for the returned set.
But wait!
This all looks fine and dandy, but there’s a couple of pitfalls here.
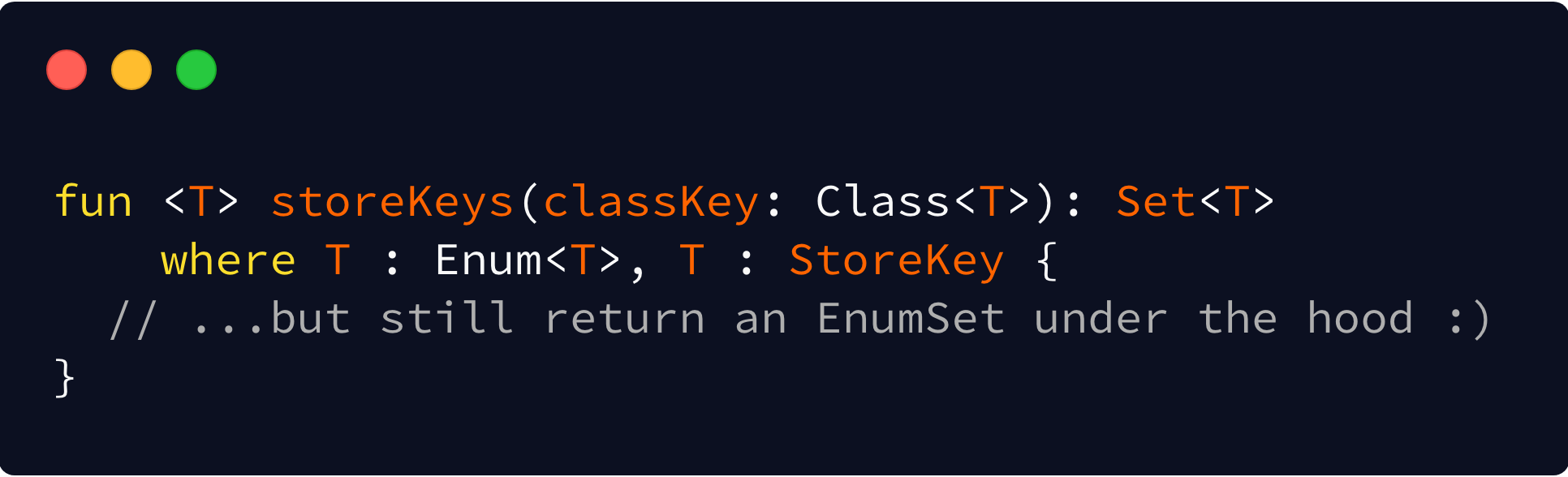
For Kotlin users, this is arguably a regression. Why? Set is immutable in Kotlin and this new API is actually returning a mutable collection. You could work around this by returning an immutable implementation instead though, such as Guava’s ImmutableEnumSet.
From a higher level though: Set is an API type, and EnumSet is an implementation set. Set allows for different implementations in the future, and keeps your API consumers agnostic to those implementations. We can still use EnumSet under the hood and get all the aforementioned benefits from before. You can see this in the aforementioned GuavaImmutableEnumSet as well: it’s not a public class, just an implementation detail.
Usability
There’s one last optimization we can make here, but it’s unique to Kotlin. If we make the function inline, we can mark the type parameter T as reified. This allows us to remove the classKey argument all together and retrieve it from the type directly.
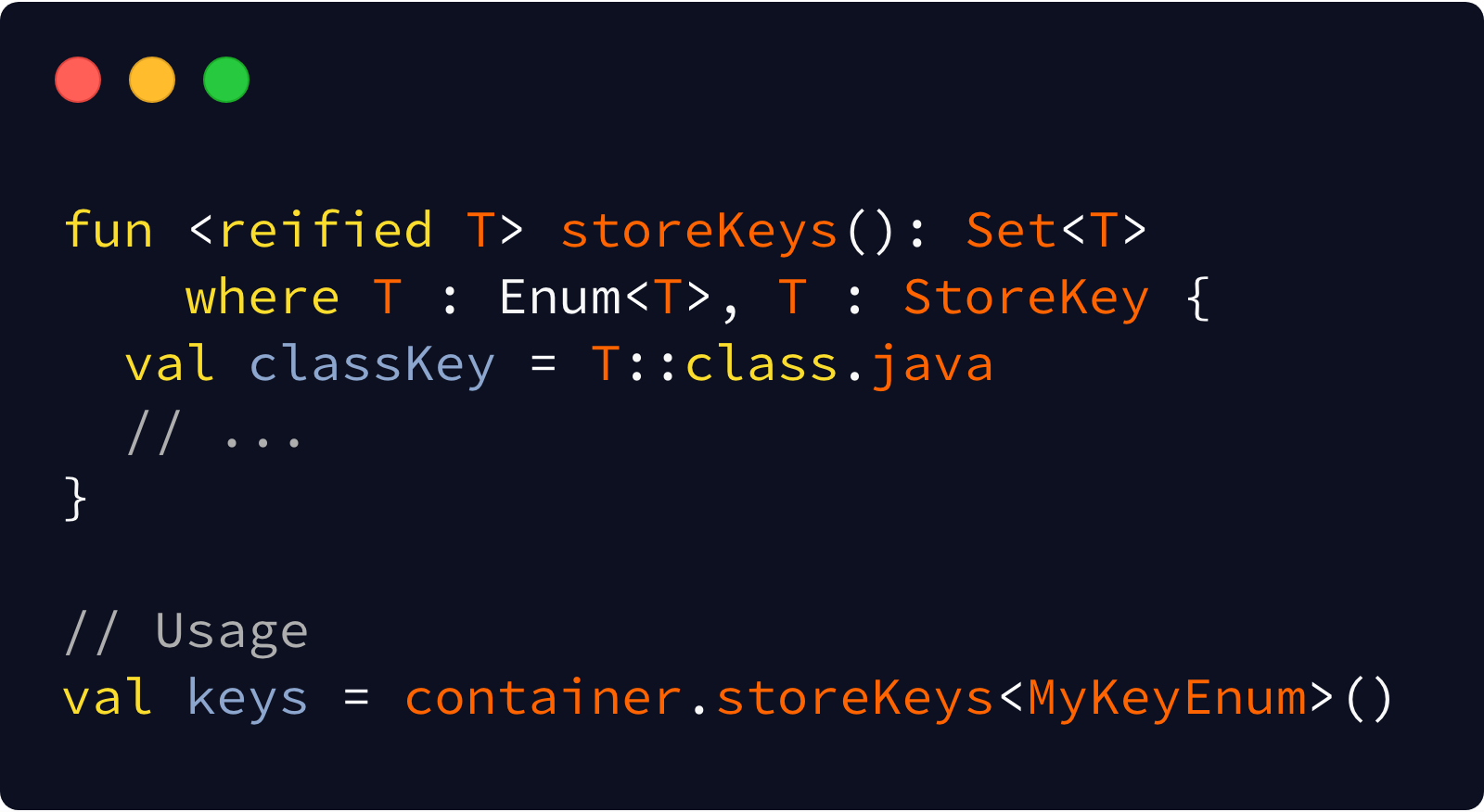
This comes at a cost though:
- It’s a breaking API change. For Kotlin consumers— it’s a signature change. For Java consumers — It’s effectively deleting the API, because Java can’t call
reifiedfunctions. You could get around this by adding thereifiedfunction as an overload though, but at the cost of adding API surface area. inlineis not free. If your function is huge, it may bloat your app. If it accesses other private APIs internal to your library, you can’t mark itinlinewithout exposing them too. You have to decide! I personally try not to useinlineif the function is more than ~10 lines or requires making other private functionspublic/inlinewith it.
While a little thing, this nicely captures how tradeoffs have to be considered for what might initially seem like an obvious win. Our storage code is actually written in Java, so we couldn’t do this change if we wanted to. Even if it was in Kotlin though, we probably would have opted against due to the usage of other private APIs in its implementation.
Takeaways
- Prefer exposing API types, not implementation types
- Be mindful of mutability changes
- And most importantly
Let the compiler enforce APIs for you!
Special thanks to Jesse, Florina, and Oleg for the feedback on this!
Header photo by Daniele Levis Pelusi on Unsplash
This was originally posted on my Medium account, but I've since migrated to this personal blog.