
For context — see the introduction post. This is part of a series of technical deep dives into different things I’ve learned along the way.
This post assumes some prior knowledge of OkHttp, Retrofit, and REST APIs.
In CatchUp, each service talks directly to that service’s API. If I were a company, I’d write some abstraction on backend and consume through that. I’m not a company though. I also wanted to do some practice with using different APIs. This blog is an account of how each one’s special in its own way. There’s no real overarching technical takeaway here other than some neat clever solutions along the way.
This did end up being a little longer than expected, so if you’re just interested in specific APIs, here are clickable links to their sections:
Hacker News
Hacker News’ API is powered by Firebase. Firebase has extensive SDKs available, but when I started working on CatchUp, Firebase wasn’t the “Play Services 2.0” juggernaut that it is now. In its initial implementation, CatchUp read directly from the JSON representation of the API.
This API basically had two endpoints: “get the top stories IDs” and “get a story by ID”. Firebase is a database after all, so the “top stories” would literally just return a list of 500 IDs, each requiring you to manually go fetch each story by that ID.
In case it wasn’t obvious: you had to make 501 network requests if you wanted to get the front page and all 500 stories.
Obviously I didn’t want to do that, so I just… cut it off at the first 50 😅
Clearly even that isn’t ideal. First and foremost, it was slow. To preserve order, the naive early implementation just used concatMap and called it a day. This meant waiting for 50 synchronous network requests to finish before showing any data. This had to be faster to be considered anywhere useable. To achieve this, I tried a couple approaches:
- Keep a list of the initial IDs, fling them to an inner
flatMap, and finally sort theflatMapresults on the original list. This was basically how it worked for a time. - Some time later, RxJava added a new
ParallelFlowabletype and I decided to try it out. The implementation was fairly similar to #1’s and still required keeping the original list to sort. It was faster, but I’m not sure if it was because it could parallelize sorting in some way too or something else. - Finally — I learned about this magic
concatMapEageroperator. This beat all the above in terms of speed and maintained order. This also didn’t require any manual state management, it was justconcatMapwith eager subscription to subsequent items. Exactly what I needed.
So now speed was solved, but the sheer network overhead was still an issue. I had tried at some point to use the Android SDK for Firebase, but Hacker News’ instance wasn’t updated to support the new clients until a long time later. When that did happen though, I gladly dropped in the SDK to read their DB, along with all their optimizations for connection pooling and caching. This ended up being faster than all the above. With the help of auto-value-firebase and a little Rx swizzling over the EventListener API, I arrived at its modern implementation. Best part? The lessons from the early prototypes were still applicable, and concatMapEager is still used to fetch individual items through the SDK concurrently.
Full source for this logic, as it’s a bit long to screenshot here :).
reddit is written largely in Python. The API also works really well with Python consumers, and dynamically typed languages in general. Things get rough for statically typed ones though.
Consider this example: In reddit’s API, a comment can have a list of other comments as its replies field. If there are no replies, it is "". When your eye stops twitching, proceed below.
With dynamic typing, it’s really easy to handle polymorphic types. In reddit, types can be defined as a number of different kinds. This kinds are basically IDs of different types. t1 is a comment, t3 is a link, listing is an indirection for helping with pagination, etc (there’s more). Every reddit API item is an object that contains a kind field indicating one of these, and a data field with a blob in the structure of that kind. With some advice and help, I got this working via custom adapter factory in Moshi by reading the kind first and contextually deserializing the data field based on the inferred type. I have a RedditType enum that just acts as a mapping of kinds to their represented model class.
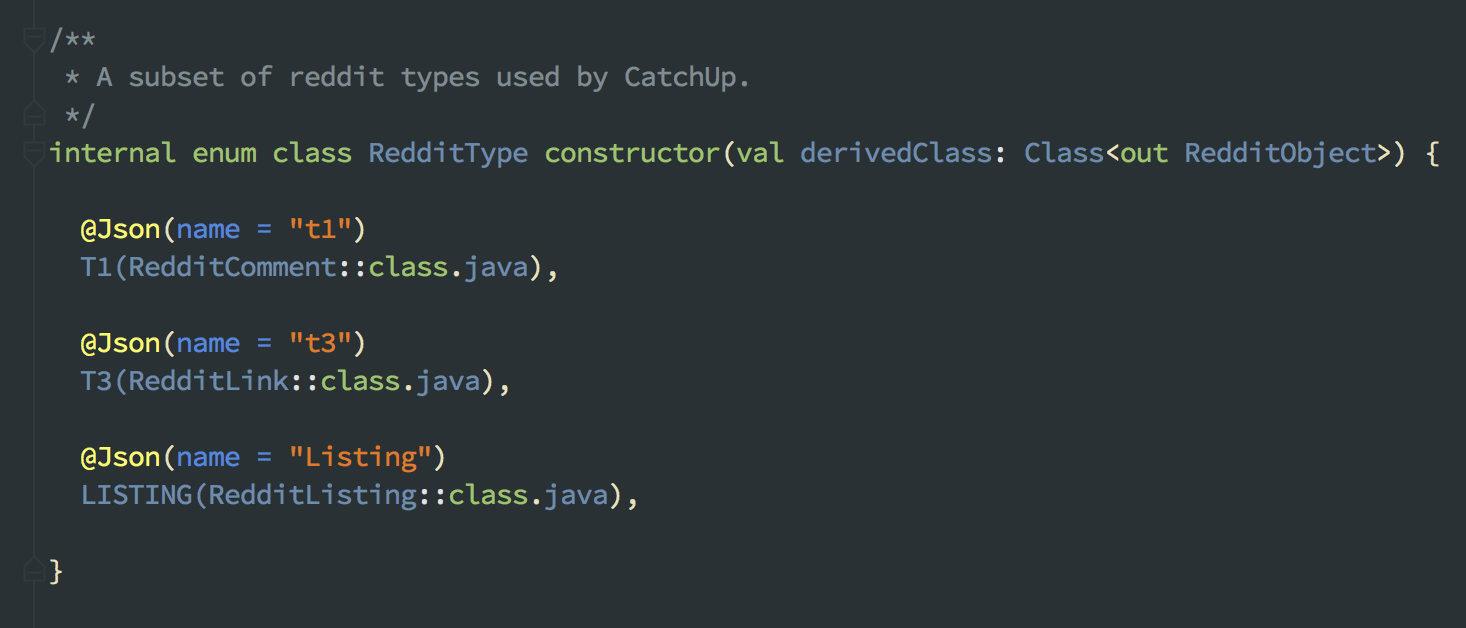
With the further help of Kotlin’s sealed classes and some other language features, this is quite tidy to deserialize with. RedditObject is the sealed class, and all the derivedClass types above are just subclasses of it.
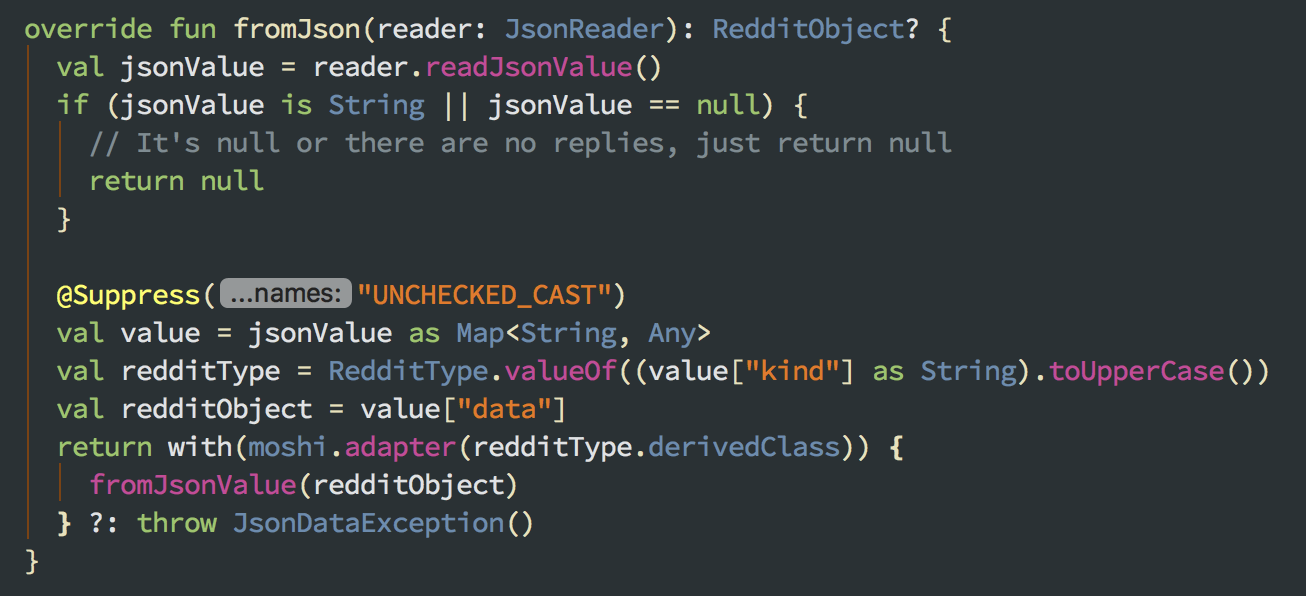
Medium
Medium doesn’t have an official public API. It does, however, support “here’s a JSON blob of everything I know about the world” if you add format=json as a query parameter to the home page URL. After some JSON spelunking, I found a section nested within the blob that appeared to have data resembling what I saw on the front page.
I found something else though. If you go to https://medium.com/?format=json, you’ll see this prefixed to the beginning of the JSON:
])}while(1);</x>{"success":true...
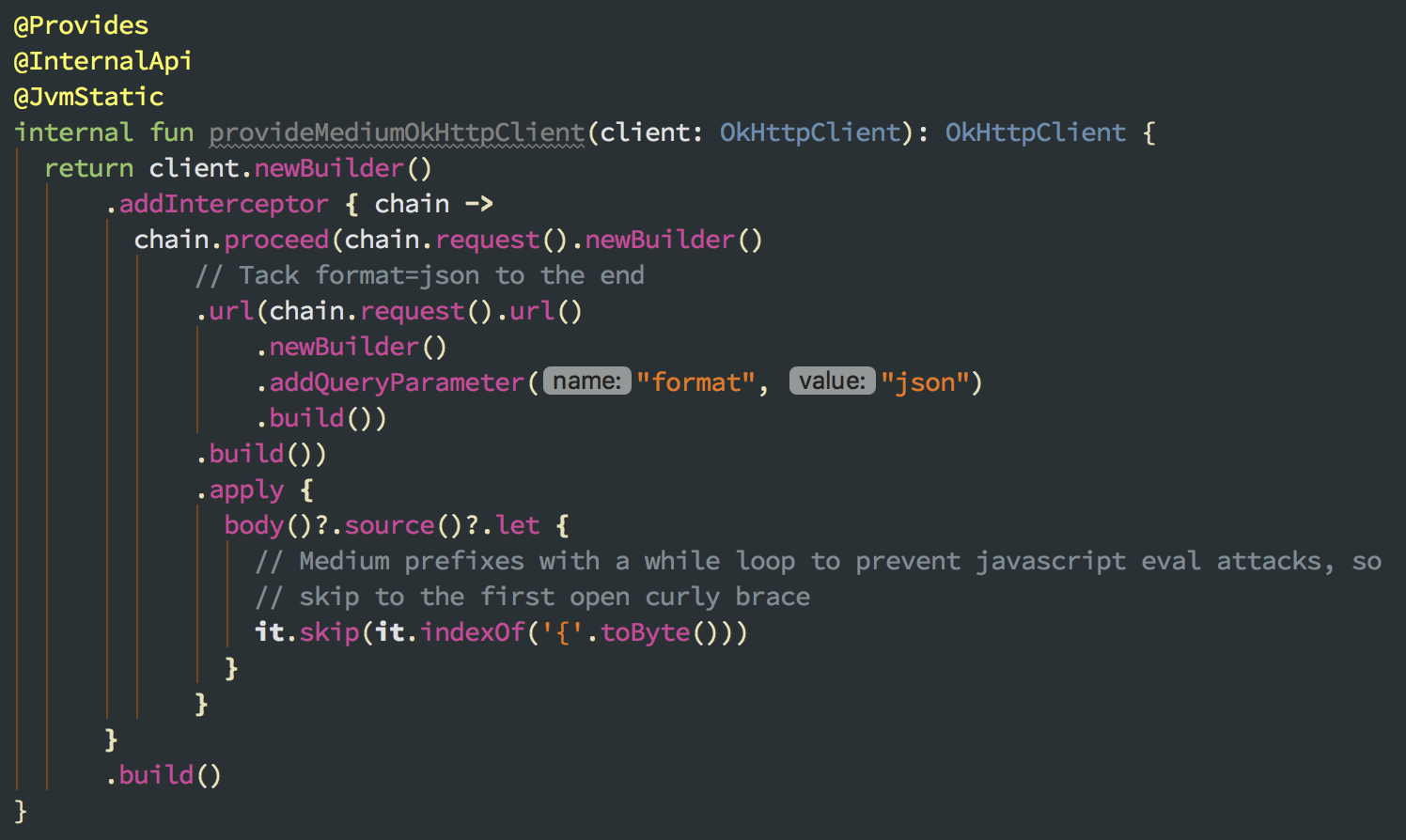
WTF is that stuff at the beginning? As far as I can tell (speculating, remember this isn’t a public API), is that this is something to prevent Javascript attacks. It’s obviously not valid JSON though, and any JSON parser is going to barf when it sees it. To get around this, I cheated it. CatchUp uses OkHttp for networking, which uses Okio under the hood. With a clever bit of IO hacking in an OkHttp interceptor, I basically just intercept the response and skip the response body source to… the first open curly brace. ¯\_(ツ)_/¯.
As mentioned higher up, the JSON dump of the front page is huge (~250kB), and mostly full of stuff we don’t need to show a front page for Medium. The actual relevant front page details are buried deep in a payload object’s references value. There’s a neat library from Serj Lotutovici called moshi-lazy-adapters, and within it is a useful annotation+adapter called @Wrapped. This annotation accepts a path that you can basically define an xpath-style path within your JSON keys to some enveloped object. In Retrofit 2, annotations on endpoints are given to converters later. When used with the 1st party moshi-converter, what this means is that any Moshi-related annotations (aka @JsonQualifier-annotated annotations) are handed directly to Moshi. This allows us to annotate an endpoint with @Wrapped and the path within the response body we want it to route to.
So instead of having to write something like this

We can write the actual signature we’re interested in and fast track to it

This saves unnecessary deserialization steps along the way and also saves us boilerplate.
Product Hunt
Product Hunt’s API is mostly great. It’s a straightforward JSON API with simple API key authentication, paging by page number, and a small footprint of data per story. Basically everything you could want in an API barring a couple gripes:
One small gripe is that it’s a bit slow. Each request in good network conditions takes about 800–900ms (vs around 400ms per page on reddit).
My main gripe about it is that it hides source URLs behind a redirecting URL of their own.
https://www.producthunt.com/r/090c08e3206f2d/116027?app_id\u003d4551 redirects to https://futuramo.com/apps/tasks?ref=producthunt
In CatchUp items, I like to show the source domain if possible. If I do that naively with these though, they’d all be the same: producthunt.com! One solution I’ve explored for this is to make a head request on these URLs during fetching. On the positive side, this completes the loop with minimal data overhead (no data, just a HEAD request). On the other, it’s not non-zero time and computational overhead. RxJava’s io() scheduler will potentially give you a new thread per request and it makes loading take substantially longer (7sec total on my Pixel 2 in good network!!).
Ultimately the time cost makes this not feasible, but how could this look if we did it? You can make a Retrofit endpoint that accepts an arbitrary URL via @Url, point it to a black hole baseUrl (say… example.com), and then feed it these URLs and consume their Results.
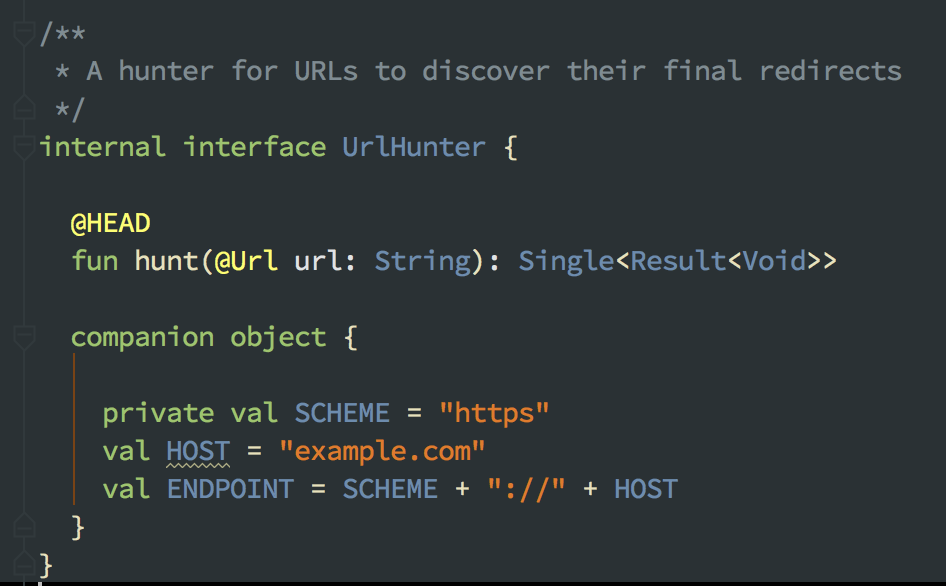
Obviously these responses won’t have a source content, but you can read their raw Response's last request (aka the final redirect) and use its URL as the “real” source domain.
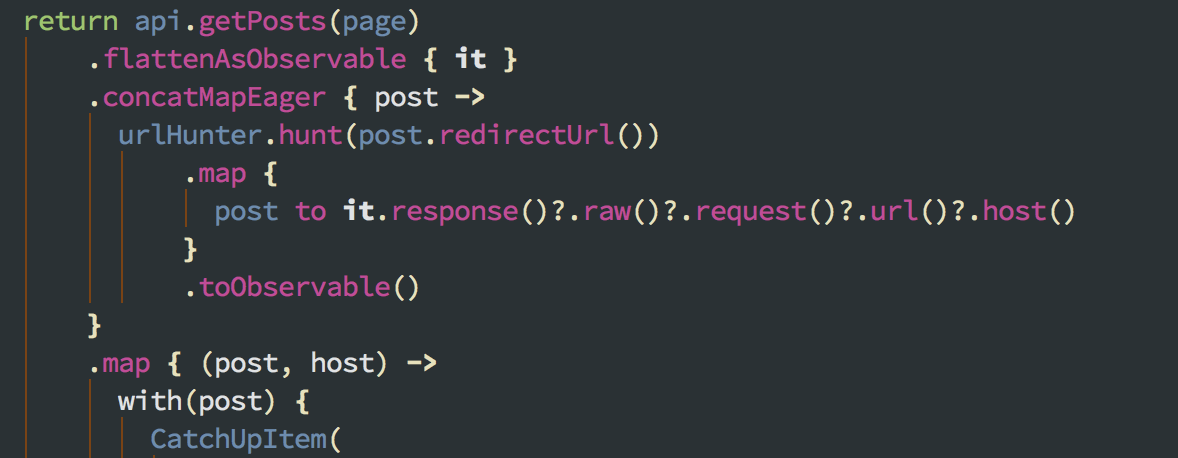
Source for this demo can be found on this branch.
Slashdot
Slashdot is a plain old RSS feed. There’s no paging and it’s all XML. Retrofit comes with first party support for an XML parser in SimpleXml. I used this initially and it worked well enough. RSS is nothing new, this section won’t be another detail about how to read RSS APIs.
What I do want to talk about here is library choice. SimpleXml worked, but its drawbacks started to show early on. I was well into using AutoValue and Moshi/Okio with all the other services by the time Slashdot came into the picture, but SimpleXml didn’t have any real support for either. When I moved CatchUp to be 100% Kotlin, it fundamentally didn’t work with it for weird annotation-related reasons I couldn’t wrap my head around. This mean I had this weird elephant in the room in a kotlin/okio/autovalue stack that didn’t use any of them. And it was also reflection-based, whereas the AutoValue model implementations I had elsewhere used auto-value-moshi to generate non-reflective adapters.
I decided to research alternatives (including writing my own dumb one as an option). Eventually I stumbled upon Tickaroo’s tikxml, an XML parsing library that supported AutoValue, custom type converters, generating adapters, had a first party retrofit converter, and used Okio under the hood. Pretty much exactly what I was looking for! Only catch was that there was no release yet. After talking with Hannes Dorfmann, they cut a release and it’s been smooth sailing ever since.
Designer News
Similar to Product Hunt in the sense that it’s mostly great, but it omits one relevant bit of detail that’s exceedingly expensive/difficult to retrieve separately. Instead of the source url though, this time it’s the author. In a previous version of Designer News’ API, the author display name was included in the item payload. In the modern version of the API though, all you get is an author ID.
Now, you can make a query to a separate endpoint with an author ID and get their info. In fact, it supports HTTP/2 and you can actually just send up a list of author IDs and get all their info in one request.

The problem here is two fold though:
1. The response payloads are huge. I don’t know quite why, but you just get an inane amount of information for each author.
2. As far as I can tell, this endpoint frequently just doesn’t work. According to someone I contacted at DN, it sends back a best effort response of information it can fulfill, but it so frequently breaks that I’m more surprised when I do see author information. To facilitate this, CatchUp retrieves the page’s stories, then tries to zip them with a flattened observable of all the fetched users for those stories’ user IDs.
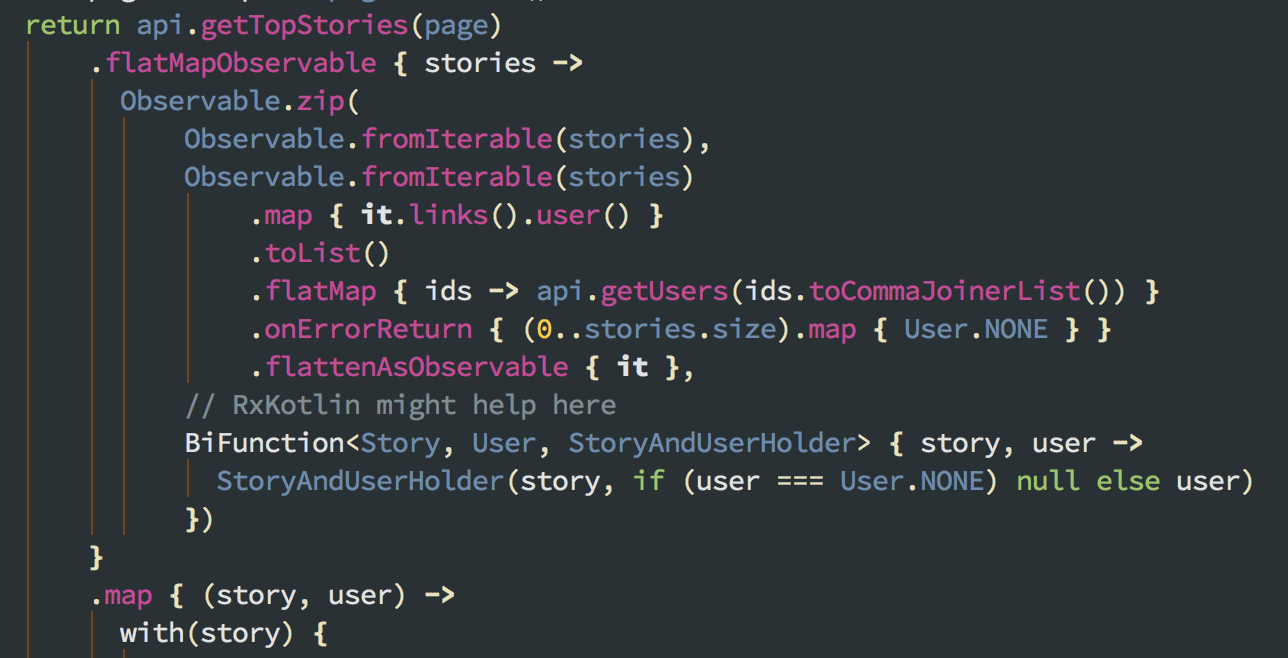
When it works, it’s a nice touch aided by a two-stage API request. When it doesn’t though, it’s a big waste of data.
Dribbble
Dribbble’s API works great, I ran into zero quirks with this. +1 would API again.
…That’s what I wrote when I started this blog post a month ago. Then Dribbble announced in late December 2017 that they were going to effectively remove all the read endpoints of their API and only allow writes (similar to Medium‘s public API). I can understand their motivation (a lot of bad eggs misusing the API and not abiding by their guidelines, thus making maintenance costly), but I’m still disappointed that this service will have to be sunset in March 2018.
GitHub
Saving the best for last, GitHub is probably the API I’ve enjoyed working with the most, mostly because I’m most excited for the technology behind it: GraphQL. Now, I’m not going to spend time here explaining what GraphQL is or why it’s useful, as there’s plenty of good material online for this. Instead, I want to focus on how it’s leveraged in CatchUp.
First and foremost: there’s the GitHub service itself. GitHub today does not expose an API for reading its Trending repositories. This is what I want to see though. How do we get this information then?
Answer: we don’t.
Instead, we fake it. GitHub’s API does support queries (specifically — what you can put in the search bar on the site). In CatchUp’s case, we send a query that basically asks for the most popular repositories created in the last week. It’s definitely not the same as GitHub’s Trending section, but it’s similar enough for me for now, and I wanted to try my hand at a GraphQL API.
To do this, CatchUp uses Apollo. Apollo is a code gen pipeline that generates Java code representations of GraphQL queries, complete with a runtime client and gradle plugin to hook into your builds. It’s not perfect, and very much a work in progress. I’ve been happy using it though, and the maintainers have been very receptive of contributions.
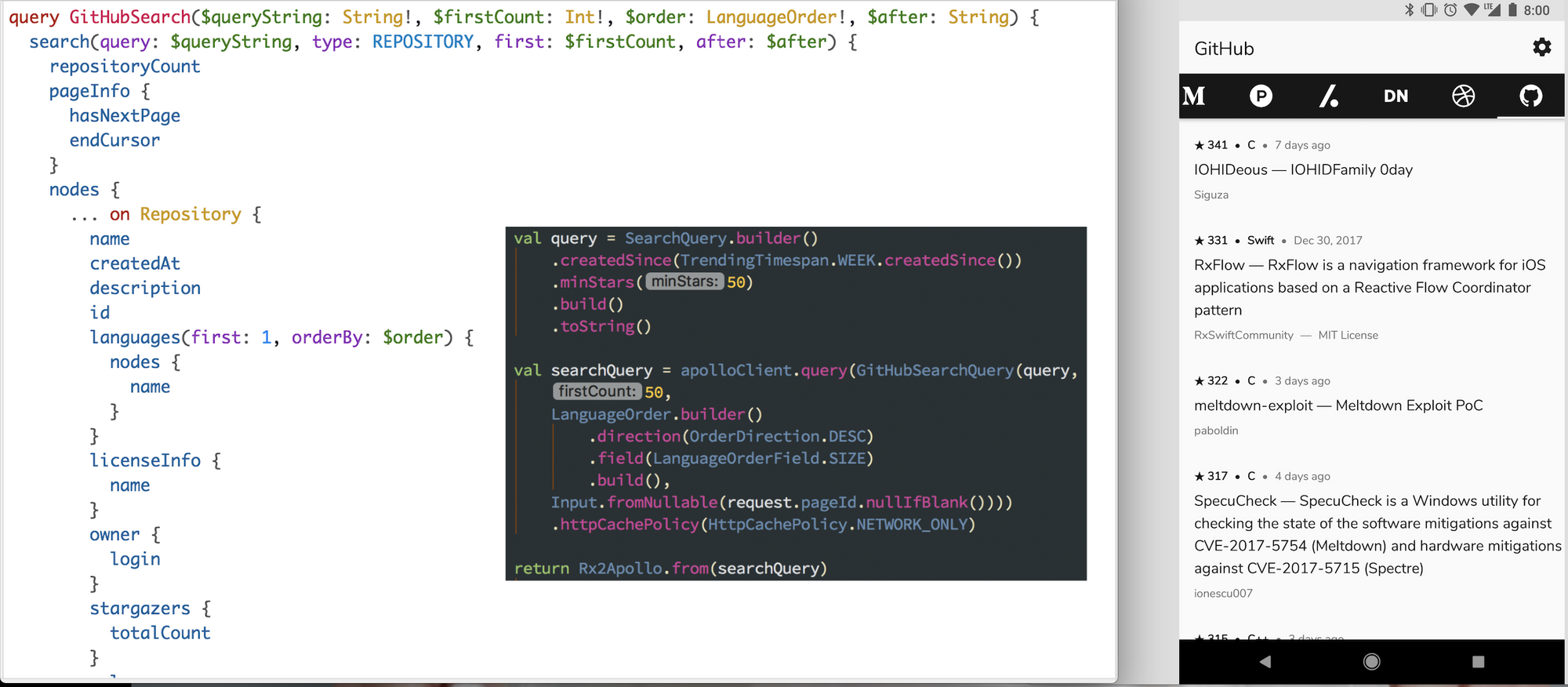
GitHub has a fantastic Explorer tool that you can use to design and work out your queries.
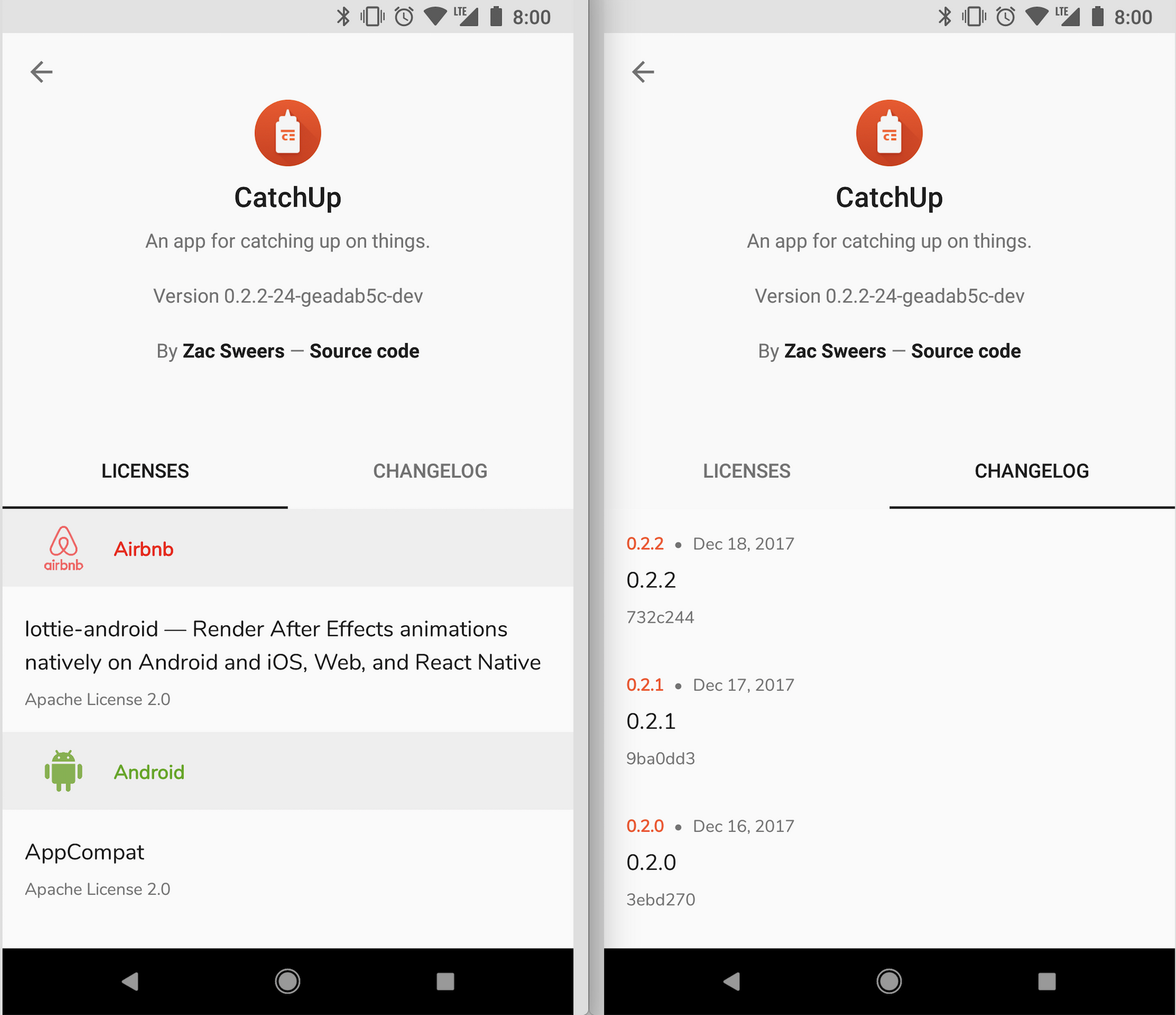
It doesn’t stop there though! The licenses and changelog data in the About screen are also dynamically queried via the GraphQL API.
The licenses bit is actually fairly interesting. I wanted to show rich data (license, name, link, avatar, etc) and didn’t want to maintain it all manually. So, we embed a simple JSON file with repo information for any dependencies on GitHub (which is most of them). A separate JSON file is included for any non-GitHub dependencies (“mix-ins”) that just have some basic information for those projects. All of these are collected in the LicensesController to form the most over-engineered RxJava chain I have ever written (100 lines!). It’s pretty neat, and I’m extremely happy with the result.
The changelog is a bit simple right now, but I plan to eventually make the items expandable to show their details.
These were all extremely custom use cases, and none of them required specific endpoints of mashing together information from multiple endpoints. GitHub knows nothing about my use case, yet I’ve solved over-fetching entirely. This is the beauty of GraphQL in action.
Another interesting thing to mention here is that GitHub has a wide variety of supported GitHub emoji. When these are passed down in the API though, they are sent as their aliases. So, instead of 👍, you get :+1:. Obviously we’d like to render these, but the work would be a bit more involved. Charles Durham contributed a really clever solution for this, and the result is we embed a pre-created sqlite DB in assets of all the “gemoji” mappings (generated from a JSON file of raw data), then use Room to load these aliases when we find matches with a regex.
Lastly, I should mention that GitHub’s GraphQL API is not complete. One example of this is creating issues, which currently is only supported in the v3 API. For debug builds, I actually wanted this so I could report bugs. From a REST standpoint, it was super simple to wire up with Retrofit, so I wouldn’t have any hesitations using it as needed in the future (despite the fact that it’s being replaced).
Future considerations
There’s plenty more to learn and do in this area. Some immediate areas I’ll be investigating in the future:
- Additive APIs. Some APIs, like Refind or RSS, only ever show you snapshots of current information. There’s no paging, no querying for older data. It would be nice to just collect this data over time and store them permanently in the DB.
- The top feature request I get is support for authentication for services. I’ve been hesitant to do this, as I worry it’s a slippery slope to becoming a full client. That said, it’s something I’m going to explore. Some APIs can’t support it (Medium and Slashdot for instance). For ones like reddit though, it’s totally doable. This adds a new layer of complexity involving tokens, managing login, etc. All of these needs to fit nicely within CatchUp’s plugin architecture as well.
And that’s it! I hope this was an interesting read. This is my second technical blog post, and definitely have a lot more to learn and improve upon. Suggestions, feedback, and criticisms are all welcome.
Thanks to Florina for reviewing this.
This was originally posted on my Medium account, but I've since migrated to this personal blog.